













Figura 1
Sistemas, estereotipos y singularidades en psicoterapia: entrevista a Marcelo Pakman Simulación Digital en Moodle para la enseñanza del desarrollo del vocabulario infantil
Estadística robusta aplicada a las medidas de localización y escala: Nota Técnica

| Autor(es) | David Ruiz Méndez, Mirna Elizabeth Quezada y Cynthia Zaira Vega Valero |
| Contacto | davidrm@tec.mx mirna.quezada@iztacala.unam.mx |
| Tipo de Contribución | Psicología de ayer y hoy |
| Referencia | Revista Digital Internacional de Psicología y Ciencia Social Vol. 6, Núm. 2, 2020. |
- Resumen
- Abstract
- Introducción
- Fundamentos teóricos
- Procedimiento empleando R
- Procedimiento usando SPSS
- Conclusiones
- Referencias
DETECCIÓN DE OUTLIERS Y MEDIDAS ROBUSTAS DE LOCALIZACIÓN USANDO R
Trabajaremos la ilustración de todos los procedimientos con una pequeña distribución de datos de tiempos entre respuestas (en milisegundos) producidos por un sujeto humano en un programa concurrente independiente IV60s-IV60s (Ruiz, 2020). Imagine que a usted le intere-sa describir el valor típico de tiempo entre respuesta en segundos producido por un participante. La estimación precisa de dicho valor, y en general la distribución de datos, dará una idea del efecto del programa de reforza-miento en la forma de responder del sujeto. Comencemos con el análisis. Los datos están organizados en un dataframe denominado datosIRT1. La única variable en este dataframe se titula IRT. Previo a analizar datos, es conveniente que conozca la estructura de su dataframe. Un comando muy útil para visualizar esta estructura es head(dataframe). En seguida ilustraremos su uso.
> head(datosIRT1)
IRT
1 2810.79
2 2799.05
3 2810.84
4 1595.15
5 2526.77
6 3416.05
Como se puede apreciar, la estructura de datos sólo tiene una columna donde se almacenan los valores in-dividuales de tiempos entre respuestas producidos en la sesión. Una vez que se conoce la estructura de la base de datos se procederá a obtener un histograma de los datos para valorar la forma de la distribución con R y detectar de manera visual la presencia de datos extremos:
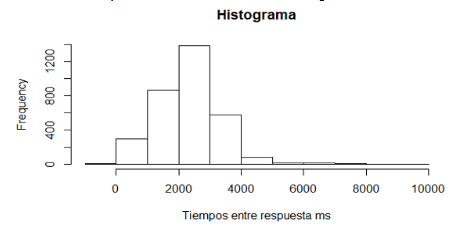
hist(datosIRT1$IRT, xlab = “Tiempos entre respuesta ms”, main = “Histograma”).
Al inspeccionar el histograma (figura 1) se detec-ta con rapidez la presencia de valores extremos en el lado derecho de la distribución. La presencia de dichos valores y el sesgo positivo resultante indica una posi-ble distorsión de las estimaciones de centralidad en este conjunto particular de datos. Se procederá entonces con el proceso de detección de valores extremos (IQR * 1.5) utilizando R:
datosextremos <− boxplot.stats(datosIRT1$IR-T)$out> datosextremos[1] 4832.53 −222.57 4886.85 4988.27 −206.41 -280.64 4798.79 −148.72 −185.94 −79.26[11] −723.45 4 858.52 4856.96 5528.52 −382.74 4 927.83 4684.69 6225.00 6427.00 5663.00[21] 5694.00 5476.00 4930.00 6271.00 4882.00 6381.00 4883.00 7066.00 4883.00 7051.00[31] 9766.00 5584.00 5522.00 7082.00 7005.00 5538.00 6942.00 6412.00 7004.00 6349.00[41] 5538.00 4852.00 7644.00 5506.00 5054.00 6443.00 7020.00 5 710.00 4898.00 5632.00[51] 6927.00 6224.00 5460.00 7753.00
El comando utiliza la función básica de estadísticas asociadas al cálculo y representación de diagramas de caja para poder computar los datos que cumplen con el criterio indicado. Los valores se almacenan en una nueva variable. El resultado del procedimiento anterior permitió conocer los valores atípicos. Dichos valores se muestran en color azul. La presencia de estos valores tiene como consecuencia que la estimación de la media aritmética resulte imprecisa para reflejar los valores típi-cos de la aglomeración central de los datos en la distri-bución de tiempos entre respuesta. Debido a esto, una opción sensible es comenzar a explorar las alternativas robustas disponibles.
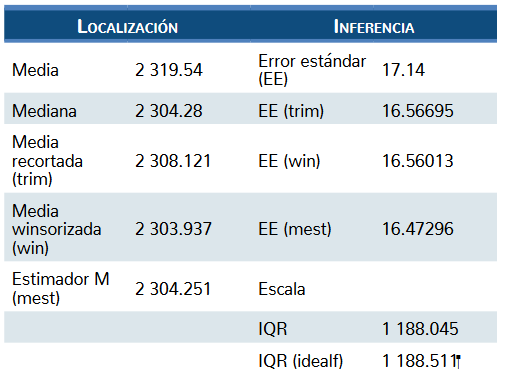
Una primera opción es utilizar una media recor-tada (Huber, 1981; Wilcox, 2017). La media recortada consiste en estimar la media a partir de una distribución que ha sido recortada de ambos extremos. La lógica de la media recortada es: podemos comenzar partiendo de un conjunto de datos de una muestra X1 . . . Xn, puestos en orden de magnitud ascendente X(1) ≤ X(2) … ≤ X(n). En esta situación podemos definir la cantidad de recorte γ, contemplando que 0 ≤γ≥ 0.5. Esto porque un corte de 0.5 sería equivalente a la mediana. Si tenemos en cuenta que g = [n γ ], redondeando el resultado anterior a un número entero, entonces la media recordada es:
𝑋𝑋!=𝑋𝑋($%&)%𝑋𝑋(()$)𝑛𝑛−2𝑔𝑔
El código para calcular una media recortada en R requiere de la instalación del paquete WRS2 (Mair y Wilcox, 2020). Una vez que el paquete es instalado, se puede calcular la media recortada con su error estándar correspondiente con el siguiente código:
library(WRS2)> mean(datosIRT1$IRT, .2)[1] 2308.121> trimse(datosIRT1$IRT, .2)[1] 16.56695
La primera línea de código llama al paquete que uti-lizaremos para los cálculos. Las siguientes líneas son los comandos para la media recortada y su error estándar. Los resultados aparecen en azul. Nótese que en ambas funciones hay dos argumentos. En todos los casos el pri-mer argumento indica el conjunto de datos y la variable de donde se va a calcular el estadístico, mientras que el segundo argumento corresponde a la proporción deseada de γ (en el caso del ejemplo, el recorte fue de 0.2).
Existen otras alternativas robustas disponibles. Una de ellas es la estimación de la media winsorizada. Este estadístico recibe su nombre en honor de Charles P. Win-sor (1895-1951). El cálculo de este estadístico tiene una lógica similar a la media recortada: Partiendo de la pro-porción delimitada en γ, los valores que entran en la pro-porción inferior y superior del recorte, en lugar de ser re-cortados, ahora son igualados al valor más chico y grande respectivamente de los valores no recortados a cada lado de la distribución. Asumiendo que el paquete WRS2 ha sido llamado, el cálculo del estadístico utilizando R es:
winmean(datosIRT1$IRT, .2)[1] 2303.937> winse(datosIRT1$IRT, .2)[1] 16.56013
Donde γ sigue siendo el argumento de la derecha en la función, el cual ahora define la porción a winsorizar.
Hay otra alternativa de estimación robusta pertene-ciente a la familia de los estimadores M, cuyo funciona-miento está basado en minimizar lo más posible funcio-nes de pérdida emergente a partir de los datos (Wilcox, 2017). La lógica de un estimador M es como sigue. Re-cuérdese que la media aritmética de una muestra mini-miza la función de pérdida de las distancias cuadráticas de los datos respecto de μ (ie. Ʃ (xi – μ) 2 ). El cálculo de un estimador M parte de la idea de cambiar la forma de la función de pérdida de diferencias cuadráticas respec-to de μ a una función de distancia respecto de un valor x. En esta nueva función, la diferencia de cada valor de la distribución se plantea con base en un nuevo valor (x) con el objetivo de minimizar al máximo las distancias resultantes al resolver para (x). De esta manera se buscaría que la derivada resultante de dicha función de dis-tancia produjera como resultado un valor de 0 a partir de estimación de x por medio de procedimientos iterativos. El valor final del parámetro x, desde el cual se cal-cula la distancia, corresponde al estimador M. Wilcox (2017) proporciona un tratamiento formalizado de esta definición. El siguiente código en R permite calcular el estimador M de una distribución y su error estándar:
> mest(datosIRT1$IRT)[1] 2304.251> mestse(datosIRT1$IRT)[1] 16.47296
MEDIDAS ROBUSTAS DE ESCALA EMPLEANDO R
Hasta el momento se han cubierto medidas de lo-calización y sus errores estándar asociados. Sin embar-go, se pueden conseguir medidas de escala más robustas para describir el segundo momento de un conjunto de datos. Una de las medidas robustas más útiles en este contexto es el rango intercuartil. El rango intercuartil es definido como la diferencia entre Q3 − Q1, calculados a partir de la distribución de datos. Una propiedad útil del rango intercuartil es que su amplitud consigue capturar la distancia cuantitativa que tiene la aglomeración de valores comunes de la distribución, aun en condiciones de sesgo o valores extremos (Hopkins y Glass, 1978). El rango intercuartil se puede calcular fácilmente en R con el siguiente código:
IQR(datosIRT1$IRT)[1] 1188.045
Una modificación más robusta del rango intercuar-til es su cálculo a partir de lo que se ha denominado ideal fourths o los cuartos ideales (Wilcox, 2017). Te-niendo en cuenta la lógica del método estándar de cál-culo de los cuartirles, las fórmulas para obtener los cuar-tiles inferior y superior a partir de los cuales se calcula el rango intercuartil modificado son:
Cuartil inferior: qi= (1 − h) X (j) + hX (j+1)Cuartil Superior: qs = (1 − h) X(k) + hX (k-1)
Donde j = [(n/4) + (5/12)], redondeado al número entero siguiente, y h = (n/4) + (5/12) − j. Teniendo en cuenta lo anterior, el nuevo rango intercuartil sería IQR = qs − qi. Utilizando el paquete WRS en R, es posible calcular los cuartiles superior e inferior con el siguiente código:
idealf(datosIRT1$IRT)$ql[1] 1710.923$qu[1] 2899.434
Por tanto, si se hace la resta entre el cuartil supe-rior e inferior, el rango intercuartil basado en los cuartos ideales sería 1,188.511.
El mejor método de comparación para demostrar la efectividad de los estadísticos robustos respecto a los estimadores estándar es su comparación a partir de un set de datos (Wilcox, 2017). ¿Cómo fue la distribución de tiempos entre respuestas de nuestros sujetos en el programa concurrente? En la tabla 1 se muestra la com-paración entre los diferentes estimadores obtenidos con cada uno de los procedimientos. El valor típico de tiem-po entre respuesta es de 2 300 m, con una amplitud de variación cuantitativa de poco más de un segundo. En la tabla se incluyen la media, la mediana y el error están-dar de los tiempos entre respuestas para su comparación con los estadísticos que hemos estado calculando. Es evidente cómo las medidas de localización robustas es-tán más a la izquierda de la distribución, acercándose al clúster de datos y compensando el sesgo positivo causa-do por los valores extremos en la distribución de datos. De hecho los estadísticos robustos de localización son más cercanos a la mediana, y por tanto más cercanos al punto modal de la distribución.

Por otro lado se puede observar la reducción en los errores estándar cuando se utilizan las alternativas robustas. Imagine que hace manipulaciones paramé-tricas en los programas concurrentes y desea comparar el valor de la media de las distribuciones de respuesta para cada programa concurrente. Las medidas robustas calculadas le permitirían obtener estimaciones de loca-lización más acertadas para cada distribución de tiempo de respuestas, así como calcular intervalos de confianza más precisos o efectuar algún procedimiento de prueba de hipótesis en el contexto de la inferencia estadística que le permita contestar sus preguntas de investigación (Casella y Berger, 2002; Huber, 1981).
ESTADÍSTICA ROBUSTA DE LOCALIZACIÓN Y ESCALA EMPLEANDO SPSS COMO SOFTWARE ESTADÍSTICO
Una vez revisados los procedimientos para obtener me-didas robustas de localización y escala de un conjun-to de datos con el software R, se procederá a revisar las posibilidades que ofrece el paquete estadístico IBM SPSS. Para tal propósito se usará el programa IBM SPSS Statistics en su versión 25 y la base de datos utilizada en el procedimiento efectuado en R con una única variable denominada IRT (“Tiempo entre respuestas”).
Al iniciar el IBM SPSS se desplegarán dos venta-nas de trabajo. La primera es la base de datos con su pestaña de “vista de datos” y “vista de variables”. En la primera pestaña se puede observar la columna con la variable IRT, y en filas el número de casos o datos para esta variable. En la pestaña “vista de variables” se ofre-cen en lista las variables activas en nuestra base de datos para ser configuradas, ordenadas y definidas (figura 2). Para más información acerca del manejo de bases de datos en SPSS, se puede consultar la documentación del software estadístico en el siguiente enlace https://www.ibm.com/support/pages/node/618179. La segunda ven-tana de trabajo corresponde a la hoja de resultados, la cual desplegará la información solicitada al software estadístico, desde los parámetros estadísticos, tablas y gráficos solicitados.

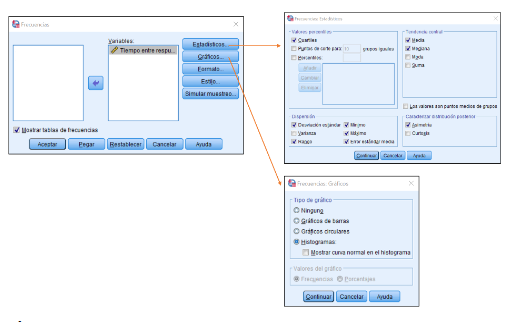
Un primer paso es explorar la simetría de la dis-tribución para detectar posibles sesgos que pudieran afectar las medidas de localización. Para hacer esto, el investigador puede servirse de un análisis visual de los datos por medio de un histograma. Adicional a la producción del histograma, el SPSS permite computar al mismo tiempo los estadísticos descriptivos de la distri-bución. Dicha solicitud puede hacer de múltiples mane-ras dentro del software estadístico. Para este ejercicio se mostrarán sólo dos métodos. El primer procedimiento es: Menú “Analizar”, seleccionamos el submenú “Estadísticos descriptivos” y después “Frecuencias”. Al ejecutar este comando se desplegará la interfaz de solicitud en la cual se deberá seleccionar la variable a analizar, en este caso IRT. Para solicitar los estadígrafos, se hace clic en “Estadísticos” y seleccionamos los que sean de nuestro interés. Para efectos prácticos se recomienda la media, mediana, desviación estándar, rango, mínimo, máximo, error estándar de la media, asimetría y cuartiles. Por otra parte, para solicitar el histograma damos clic en “Gráfi-cos” y solicitamos la opción de histograma. La serie de selecciones se muestra en la figura 3. Una vez hecho esto, se acepta la solicitud con lo cual se desplegará el análisis en la ventana de resultados.

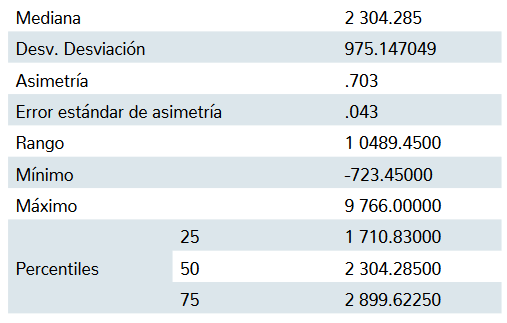
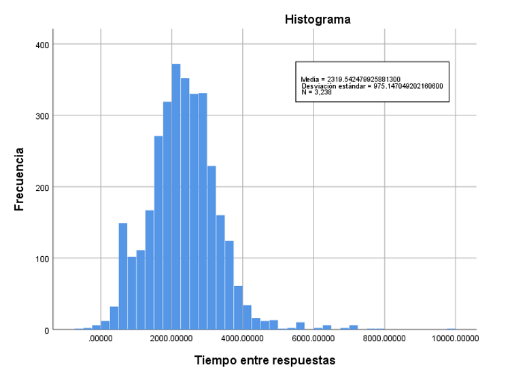
El análisis visual exploratorio de la distribución por medio del histograma muestra datos atípicos y aislados en el lado derecho del gráfico, lo cual se puede inter-pretar como una distribución asimétrica positiva con la presencia de una concentración de valores extremos a la derecha de la distribución (figura 4). Al inspeccionar la tabla 2 se confirma esta situación al obtenerse un valor positivo de la asimetría (0.703), así como la ligera incon-sistencia entre la media y la mediana que, en distribu-ciones con colas simétricas, deberían coincidir al centro de la distribución (Rosenberg y Gasko, 1983).
Warning: imagepng(/mnt/proyectos/all_backup/html/cuved/public_html/rdipycs/wp-content/uploads/2020/09/Tabla-2_1-2-160x135.png): failed to open stream: Permission denied in /mnt/proyectos/all_backup/html/cuved/public_html/rdipycs/wp-includes/class-wp-image-editor.php on line 425


Para dar seguimiento a estos hallazgos, conviene hacer un análisis minucioso de las características de la distribución mediante un diagrama de cajas (boxplot), un gráfico de tallo y hojas, y la obtención de estimadores ro-bustos de localización. Para hacer esta solicitud en SPSS se debe seguir la siguiente ruta: Menú “Analizar”, sub-menú “Estadísticos descriptivos” y se da clic en “Explo-rar”, lo cual desplegará una interfaz ligeramente distinta al procedimiento anterior. Tenemos que seleccionar la variable de interés a la casilla “Lista de dependientes”, y comenzamos solicitando en el apartado “Estadísticos” los descriptivos, los estimadores M y los valores atípicos. Asi-mismo, en el apartado “Gráficos” se seleccionarán “De tallo y hojas” e “Histograma” (figura 5).Comenzaremos con los gráficos, analizando el grá-fico de tallo y hojas solicitado (figura 6). Básicamente consiste en un compilado de los datos de manera sim-plificada que muestra la distribución vertical de la varia-ble medida. Este tipo de gráficos se usa para explorar los datos en conjunto de manera visual mostrando tallos a manera de filas, y hojas por cada dato en cada fila. En la columna Stem se encuentra el primer dígito del dato, mientras que en las hojas se localiza el segundo dígito de cada dato. Para conocer la unidad de medida de refe-rencia que se está sintetizando, se explora el “Ancho del tallo”. En este caso es de 1000.00 (en milisegundos). Por tanto, en este caso el dígito del tallo en conjunto con el dígito de la hoja debe entenderse como “miles de milise-gundos”. Por ejemplo, tallo 4 y hoja 6 constituirán el dato 46,000.00. La columna “Frecuencia” muestra el número de veces que el dato 46,000.00 aparece en nuestra distri-bución. En este ejemplo, el 46,000.00 se presenta en tres ocasiones. Este gráfico también permite la detección de los datos extremos de nuestra distribución.


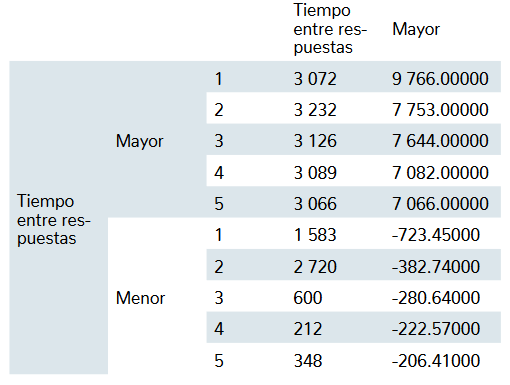
En la figura 6 se muestra cómo el software ubica ocho casos atípicos al lado izquierdo de la distribución, los cuales son <−79.00, y cómo detecta 46 casos atípi-cos a la derecha de la distribución >4685.00. Para ob-servar estos datos, el investigador puede remitirse a la tabla dinámica que proporciona el software en la hoja de resultados, en los cuales están los datos enlistados en orden ascendente. Asimismo, en conjunto con el gráfico de tallo y hojas y la lista ascendente de la variable, el in-vestigador puede remitirse a la tabla de valores extremos solicitados, en la cual están los cinco valores extremos de la distribución mayores y menores, así como su nú-mero de caso (tabla 3).

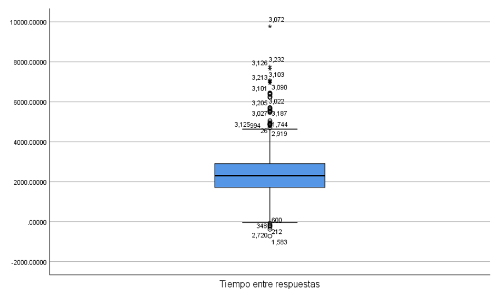
Podemos acudir a otra forma de representación gráfica que puede proporcionar información directa de valores extremos de alta influencia. Emerson y Stre-nio (1983) indican que los diagramas de caja y bigote son efectivos para determinar la localización, disper-sión, asimetría, longitud de las colas y los outliers en una distribución basado en la síntesis de cinco medi-das principales: límite inferior, primer cuartil, mediana, tercer cuartil y límite superior. De modo que los datos que están alejados de los límites superiores e inferiores son considerados como valores atípicos y deben recibir especial atención. Una de las características más atrac-tivas de este gráfico es que refleja una imagen comple-ta del comportamiento de los datos. Para explorar los datos nos remitiremos al primer (figura 3) y segundo procedimiento (figura 5), en el cual se obtuvieron los puntos de cortes por cuartil, mientras que en el segundo procedimiento se obtuvo el rango intercuartil (tabla 2). Así, Q3 = 2 899.62250- Q1 = 1 710.8300 arroja un ran-go intercuartil de 1 188.793. A su vez este dato permite conocer el límite inferior y superior de nuestra distribu-ción, así L_i=Q_1-3/2 d_F, mientras que L_s=Q_1+3/2 d_F. Todo dato fuera de estos límites correspondería a casos extremos. El segundo procedimiento proporciona por defecto el diagrama de caja, como se muestra en la figura 7. La caja o el espacio intercuartilar corresponde a 50 de la distribución alrededor de la mediana. Fue-ra de los bigotes se localizan los outliers con un círcu-lo y los valores atípicos extremos con un asterisco. La diferencia entre uno y otro es que los valores atípicos extremos se alejan del cuartil inferior y superior 2 3/2 d_F, y como se ha indicado, deben tratarse con mucho cuidado (Milton, 2007). Además, el diagrama de caja producido por SPSS indica el número de caso en que se presentan las anomalías para que al investigador le sea posible estimar con facilidad el grado de recorte o win-sorización a efectuar en la distribución.

Una vez confirmada la presencia de valores extre-mos en la distribución, se puede tomar acción sobre los datos. Field (2013) indica varias acciones para reducir la influencia del sesgo en nuestros datos empleando IBM SPSS: 1) recortar la distribución; 2) winsorizar los datos para obtener la media (de manera manual), y 3) solici-tar medidas robustas, como los estimadores M (calculado por SPSS). La primera opción implica recortar nuestra dis-tribución eliminando datos extremos. En caso de recurrir al método de recorte, el investigador puede obtener una media recortada (revisada y comentada en el procedi-miento empleando R). La media recortada se obtuvo con IBM SPSS mediante el segundo procedimiento revisado (figura 5). El resultado proporciona estadísticos descripti-vos, entre los que se encuentra la media recortada a 5sin posibilidad de ajustar este valor (tabla 4). De esta ma-nera el software calculó la media aritmética de la distribu-ción recortada 5 a cada cola de X1 … Xn,.

En lugar de recortar las colas de la distribución, una segunda opción implica winsorizar la distribución de acuerdo con un porcentaje preestablecido. Sin embargo este procedimiento es manual. Primero se transforma la distribución original a las puntuaciones estandarizadas o z-scores, dando como resultado una distribución nor-mal con media en 0 y con desviación estándar de 1. El remplazo de valores en este procedimiento se hace teniendo en cuenta que todo aquel valor < −2.58 o > +2.58 de z-scores representa un outlier, mientras que los valores extremos pueden categorizarse de esta manera al encontrarse >3.29 z-scores (Field, 2013).
La transformación a puntuaciones z y localización de extremos puede hacerse en el IBM SPSS con el si-guiente procedimiento.
Transformación a puntuaciones estandarizadas. Menú “Analizar”, submenú “Estadísticos Descriptivos”, sin hacer cambios en los apartados de la derecha, sólo seleccionamos en la interfaz la casilla “Guardar valores estandarizados como variables”. Al hacer esto se añadirá a nuestra ventana de datos una nueva columna de varia-ble con la etiqueta Puntuación Z, en este caso ZIRT.
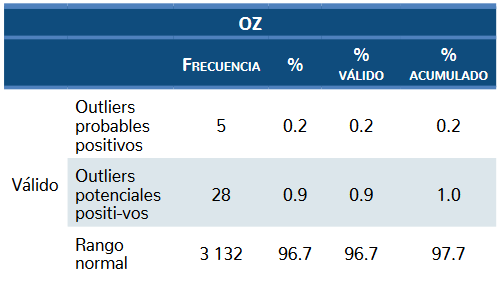
Categorización de extremos. Para clasificar en ca-tegorías con base en la probabilidad de casos en segmen-tos de la curva, iremos al menú “Transformar” y submenú “Recodificar en distintas variables”, seleccionaremos las puntuaciones estandarizadas transformadas con el paso an-terior, y colocaremos un nombre y etiqueta para esta nue-va variable. Para determinar los valores que constituirán cada categoría damos clic en “Valores antiguos y nuevos” y categorizamos por nivel de probabilidad de la siguien-te manera: (3.2901 thru Highest=4) (2.5801 thru 3.29=3) (1.9601 thru 2.58=2) (-1.9601 thru 1.96=1) (-2.5801 thru -1.96=-2) (-3.2901 thru -2.58=-3) (Lowest thru -3.29=-4). Después se deberán nombrar las categorías con base en los valores desde la vista de variables de la siguiente ma-nera: -4=Extremos positivos; -3=Outliers probables positi-vos; -2=Outliers potenciales positivos; 1=Rango normal; 2=Outliers potenciales negativos; 3=Outliers probables negativos; 4=Extremos negativos.
Identificación de extremos. Menú “Analizar”, sub-menú “Estadísticos descriptivos”, seleccionamos la op-ción “Frecuencias”, dejamos la sección “Estadísticos” en blanco al igual que “Gráficos” y el resto de los subme-nús; en la interfaz seleccionamos la casilla “Mostrar ta-blas de frecuencias” y ejecutamos el análisis. En la hoja de resultados se observará una tabla similar a la tabla 4, en la cual se muestra la frecuencia de cada categoría y el porcentaje con relación a la distribución en su totali-dad. El investigador tendrá la posibilidad de conocer el porcentaje de sus datos extremos y probables outliers que comprometen la distribución con una asimetría po-sitiva, y por consiguiente su media aritmética.
Reemplazo de valores extremos. En IBM SPSS no hay una solicitud específica para winsorizar una distribu-ción, por lo cual el procedimiento debe hacerse de ma-nera manual para obtener la media winsorizada. La tabla de frecuencias obtenida en el paso anterior, en conjunto con el gráfico de tallo y hojas, así como la tabla dinámica de valores ascendentes y valores extremos, permitirán al investigador conocer el dato concreto a remplazar. Por ejemplo, en esta distribución podrían remplazarse los va-lores >4685.00 con base en el gráfico de tallo y hojas (fi-gura 7), o los cinco valores extremos mayores y menores de la distribución con base en la tabla de valores extre-mos (tabla 3). Para remplazar es necesario seleccionar la columna de la variable en cuestión en la base de datos, y dar clic en el ícono de búsqueda y remplazo para teclear el valor específico, o ir al menú “Editar” y después “Ir al caso” para remplazar de modo manual el valor extremo, y posteriormente volver a solicitar los estadísticos des-criptivos con el primer procedimiento (figura 3), lo cual arrojará la Media de la distribución Winsorizada.
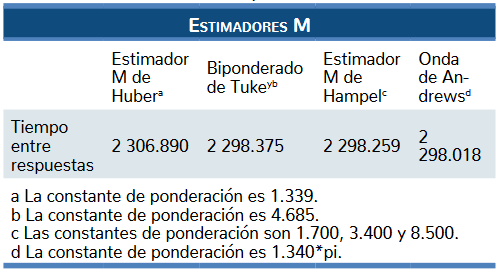
La tercera opción robusta proporcionada por el pro-grama IBM SPSS son los estimadores M. Esta solicitud al software se hizo en el segundo procedimiento revisado antes (figura 5) al seleccionar la casilla “Estimadores M”. Como se muestra en la tabla 5, el software proporciona cuatro diferentes tipos de estimadores. Los más usados son el estimador Huber y el Biponderado de Tukey. El primero está recomendado para distribuciones que se pueden adaptar más a una distribución Gaussiana, por-que pierde eficiencia en casos contrarios. En cambio, el segundo es elegido en situaciones en que hay valores extremos que pronuncian las colas de nuestra distribu-ción. De esta manera, la función pondera con 0 los da-tos mientras más se alejan del estimador, con lo cual pierden su influencia (Wilcox, 2017; Goodall, 1983).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cómo citar:APA6 |
Ruiz-Méndez, D., Quezada, M. E., & Vega Valero, C. Z. (2020). Estadística robusta aplicada a las medidas de localización y escala: Nota Técnica. Revista Digital Internacional De Psicología Y Ciencia Social, 6(2), 499-517. https://doi.org/10.22402/j.rdipycs.unam.6.2.2020.302.499-517
|